추상화
어떤 것들의 공통적인 성격을 뽑아내어 이를 따로 분리해내는 작업
인터페이스
자바가 추상화를 위해 제공하는 유용한 도구
어떤일을 하겠다는 기능만 정의해 놓을 것
자신이 사용할 클래스가 어떤 것인지 몰라도 단지 인터페이스를 통해 원하는 기능을 사용하기만 하면 된다.
개방 폐쇄 원칙
객체지향 설계 원칙 중 하나
클래스나 모듈은 확장에는 열려있어야 하고 변경에는 닫혀있어야 한다.
객체지향 설계 원칙(SOLID)
객체지향의 특징을 잘 살릴 수 있는 설계의 특징
디자인 패턴이 구체적인 솔루션이라면 객체지향 설계 원칙은 general한 설계 기준
5가지 객체지향 설계 원칙
1. SPR(The Single Responsibility Principle): 단일 책임 원칙
하나의 메서드에는 하나의 기능
2. OCP(The Open Closed Principle): 개방 폐쇄 원칙
확장에는 열려있지만 변경에는 닫혀있다
3. LSP(The Liskov Subsitution Principle): 리스코프 치환 원칙
다형성
4. ISP(The Interface Segregation Principle): 인터페이스 분리 원칙
사용자마다 창 분리하여 구현
5. DIP(The Dependency Inversion Principle): 의존관계 역전 원칙
사용할 객체 불러쓰기
높은 응집도
하나의 모듈, 클래스가 하나의 관심사에만 집중
변경이 필요할 때 해당 모듈, 클래스가 전체적으로 변함
낮은 결합도
결합도: 하나의 오브젝트가 변경이 일어날 때에 관계를 맺고 있는 다른 오브젝트에 변화를 요구하는 정도
책임과 관심사가 다른 오브젝트, 모듈은 느슨하게 연결된 상태를 유지
변화에 대응하는 속도가 높아지고 구성이 깔끔해진다.
전략 패턴
자신의 기능 맥락(컨텍스트)에서 필요에 따라 변경이 필요한 알고리즘을 인터페이스를 통해 통째로 외부로 분리시키고 이를 구현한 구체적인 알고리즘 클래스를 필요에 따라 바꿔 사용할 수 있도록 해주는 디자인 패턴
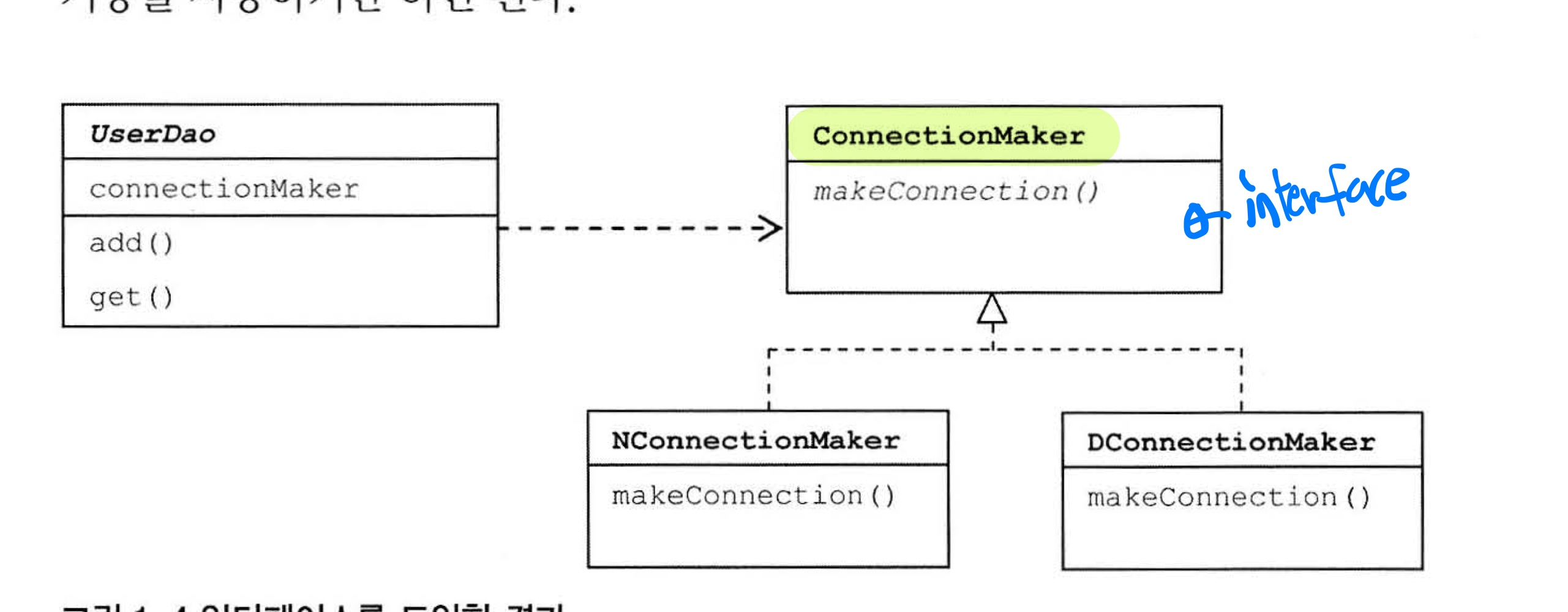
ex) 책의 개선한 UserDaoTest-UserDao-ConnectionMaker 구조
개방 폐쇄 원칙에 잘 들어맞는 패턴
+읽고 느낀 점
인터페이스라는 개념이 처음 나왔는데 객체지향 설계 원칙에 상당히 부합하는 유용한 도구인 것 같다.
1장에서 전체적으로 객체지향 원칙에 관한 내용들이 많이 나왔는데 스프링이 자바의 퇴색된 객체지향 원칙을 보완하기 위해 나온 프레임워크인만큼 스프링을 잘 이해하기위해선 객체지향 원칙을 잘 이해하고 있는 것이 중요할 것 같다는 생각이 들었다.
참여하고 있는 스프링 스터디에서 책에는 전략 패턴이 간단하게 나왔지만 현업에서 중요한 개념인 것 같다고 말을 해주셔서 전략 패턴에 대해 좀 더 공부해보면 좋을 것 같다.
'Spring > 토비의 스프링' 카테고리의 다른 글
| [토비의스프링3.1] 1.5 스프링의 IOC (0) | 2022.01.21 |
|---|---|
| [토비의스프링3.1] 1.4 제어의 역전(IoC) (0) | 2022.01.21 |
| [토비의스프링3.1] 1.2 DAO의 분리 (0) | 2022.01.13 |
| [토비의스프링3.1] 1.1 초난감 DAO (0) | 2022.01.13 |
| [스프링] 스프링의 중요한 특징과 공부 방향 (0) | 2022.01.05 |

